Research
Current Projects (Under Construction)
Improving RL through Demonstrations
Many learning (Sherstan et al., 2020) methods such as reinforcement learning suffers from a slow beginning especially in complicated domains.
The motivation of transfer learning is to use limited prior knowledge to help learning agents bootstrap at the start and thus achieve overall improvements on learning performance. Due to limited quantity or quality of prior knowledge, how to make the transfer more efficient and effective remains an interesting point.
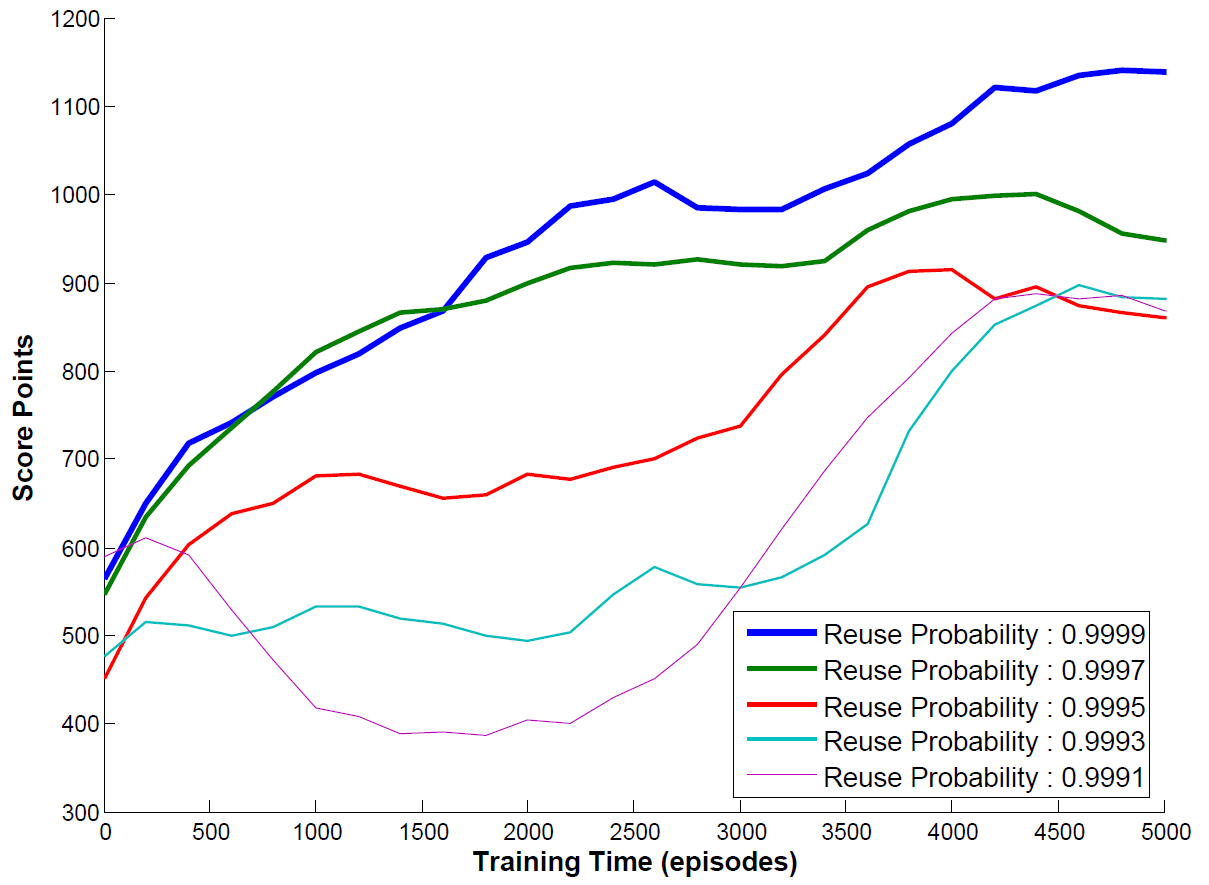
Teaching through Action Advice
We developed an advice model framework to provide theoretical and practical analysis for agents to teach humans and agents in sequential reinforcement learning tasks. The teacher agents assist the students (humans or agents) with action advice when the teachers observe the students reach some critical states. Assuming the teachers are optimal, the students will follow the action advice to achieve better performance.
Training Agents with Discrete Human Feedback
In this project, we consider the problem of a human trainer teaching an agent via providing positive or negative feedback. Most existing work has treated human feedback as a numerical value that the agent seeks to maximize, and has assumed that all trainers will give feedback in the same way when teaching the same behavior.
In contrast, we treat the feedback as a human-delivered discrete communication between trainers and learners and different training strategies will be chosen by them. We propose a probabilistic model to classify different training strategies. We also present the SABL and I-SABL algorithms, which consider multiple interpretations of trainer feedback in order to learn behaviors more efficiently. Our online user studies show that human trainers follow various training strategies when teaching virtual agents and explicitly considering trainer strategy can allow a learner to make inferences from cases where no feedback is given.
Representative papers: (MacGlashan et al., 2017) (Peng et al., 2016) (Loftin et al., 2015)
